[1] "A média do conjunto de dados é: 29.4"Probabilidade e Estatística
Medidas de Posição e Separatrizes
Professor: Leonardo Brandão Freitas do Nascimento
Introdução
As medidas de tendência central são estatísticas usadas para resumir um conjunto de dados, indicando um valor central ou típico em torno do qual os dados se distribuem.
As principais medidas de tendência central são a média, a mediana e a moda.
Cada uma dessas medidas tem suas próprias características e aplicações, dependendo do tipo de dados e do contexto da análise
O interesse é caracterizar o conjunto de dados através de medidas que resumem as informações
Símbolos matemáticos
Para representar uma amostra de tamanho \(n\), escrevemos: \[x_1, x_2,..., x_n,\] onde \(x_i\) é a \(i\)-ésima observação em um conjunto de \(n\) observações, ou seja, \(x_1\) representa a primeira observação, \(x_2\) a segunda e assim por diante.
Considere os tempos, em segundos, de cinco tarefas realizadas por uma CPU: \[30; 25; 28;33;31. \]
Escreva esse conjunto na notação geral: \(x_1 = 30\),\(x_2 = 25\), \(x_3 = 28\), \(x_4 = 33\), \(x_5 = 31\).
Símbolos matemáticos
Em alguns momentos estamos interessados em ordenar os dados do menor valor para o maior valor, dessa forma escrevemos: \[x_{(1)}, x_{(2)},..., x_{(n)},\] onde \(x_{(1)}\) é a menor observação, \(x_{(2)}\) é a segunda menor e assim por diante.
Considere os tempos, em segundos, de cinco tarefas realizadas por uma CPU: \[30; 25; 28;33;31. \]
Ordene os dados e escreva na notação apresentada: \(x_{(1)} = 25\),\(x_{(1)} = 28\), \(x_{(3)} = 30\), \(x_{(4)} = 31\), \(x_{(5)} = 33\).
Símbolos matemáticos
Para indicarmos a soma dos valores \(x_1, x_2,..., x_n\), isto é, \(x_1+x_2+x_3+...+x_n\), utilizamos o símbolo \(\Sigma\) (letra grega maiúscula: sigma), denominado como somatório em linguagem matemática.
A soma dos valores \(x_1, x_2,..., x_n\) é escrita, de forma mais compacta, como segue: \[x_1+x_2+x_3+...+x_n = \sum_{i=1}^{n}x_i. \]
Lemos: somatório de \(x\) índice \(i\), para \(i\) de \(1\) a \(n\).
Média
Média Aritmética Simples
- A média arimética simples de um conjunto de dados é obtida somando todos os valores e dividindo o resultado pelo tamanho da amostra, ou seja, \[\mbox{Média} = \dfrac{\mbox{soma de todos os valores}}{\mbox{Tamanho da amostra}}.\]
Média Aritmética Simples
- Se as \(n\) observações em uma amostra forem denotadas por \(x_1,x_2,\ldots,x_n\), então a média amostral será \[\bar{x}=\frac{x_1+x_2+\cdots+x_n}{n}=\frac{\sum\limits_{i=1}^{n}x_i}{n}.\]
Média Aritmética Simples - Exemplo
Média Aritmética Ponderada - Exemplo
- A tabala abaixo mostra o tempo gasto (segundos) de uma CPU na realização de 20 tarefas
- As frequências podem ser observadas como o peso de cada observação.
Média Aritmética Ponderada - Exemplo
| X | fa | fr | Fa | Fr |
|---|---|---|---|---|
| 35 | 1 | 0.05 | 1 | 0.05 |
| 36 | 6 | 0.30 | 7 | 0.35 |
| 37 | 9 | 0.45 | 16 | 0.80 |
| 38 | 2 | 0.10 | 18 | 0.90 |
| 39 | 1 | 0.05 | 19 | 0.95 |
| 40 | 1 | 0.05 | 20 | 1.00 |
Média Aritmética Ponderada - Exemplo
- Para calcular a média do conjunto de dados utilizamos a média ponderada: \[\bar{x}=\frac{f_{a_1} x_1+f_{a_2} x_2+\cdots+f_{a_k} x_k}{n}=\frac{\sum\limits_{i=1}^{k}f_{a_i} x_i}{n}=\sum\limits_{i=1}^{k}x_i f_{r_i}.\]
Média Aritmética Ponderada - Exemplo
- Suponha que um aluno obteve as seguintes notas: 8 (parcial 1), 6 (parcial 2) e 9 (parcial 3). Nessa caso, a média dos exercícios escolares é: \(MEE = \frac{8+6+9}{3} = 7.67\). Sabendo que MEE tem peso 2 e a nota da prova final (peso 1) foi de 5, quanto é a nota final do aluno?
Média Aritmética Ponderada - Exemplo
- Para calcular a média do conjunto de dados utilizamos a média ponderada: \[{MF}=\frac{2 MEE+PF}{3}=\frac{2\times7.67+5}{3} = 6.78\]
Média Aritmética Ponderada - Exemplo
- A tabala abaixo mostra o tempo gasto (segundos) de uma CPU na realização de 50 tarefas
Média Aritmética Ponderada - Exemplo
| X | (34,36] | (36,38] | (38,40] | (40,42] | (42,44] | (44,46] | (46,48] | (48,50] |
| PM | 35 | 37 | 39 | 41 | 43 | 45 | 47 | 49 |
| fa | 3 | 10 | 9 | 5 | 12 | 2 | 8 | 1 |
| fr | 0.06 | 0.20 | 0.18 | 0.10 | 0.24 | 0.04 | 0.16 | 0.02 |
| Fa | 3 | 13 | 22 | 27 | 39 | 41 | 49 | 50 |
| Fr | 0.06 | 0.26 | 0.44 | 0.54 | 0.78 | 0.82 | 0.98 | 1.00 |
Média Aritmética Ponderada - Exemplo
- Para calcular a média do conjunto de dados utilizamos a média ponderada: \[\bar{x}=\frac{\sum_{i=1}^{k}f_{a_i} PM_i}{n}=\sum\limits_{i=1}^{k}PM_i f_{r_i},\] em que \(PM_i\) é o ponto médio da classe \(i\)
Moda
A moda de uma variável é o valor que ocorre com mais frequência, ou seja, aquele que mais se repete.
Se dois valores ocorrerem com a mesma frequência máxima a variável é bimodal;
Se mais de dois valores ocorrem com a mesma frequência máxima, a variável é multimodal;
Quando nenhum valor se repete, a variável não tem moda.
A moda do conjunto de dados será denotada por \(Mo\).
Dados não agrupadados - Exemplo
Considere as seguintes séries de dados e identifique a moda:
7, 8, 9, 10, 10, 10, 11, 12, 13, 15
3, 5, 8, 10, 12, 13
2, 3, 4, 4, 4, 5, 6, 7, 7, 7, 8, 9
Dados agrupadados - Exemplo
- A tabala abaixo mostra o tempo gasto (segundos) de uma CPU na realização de 50 tarefas
- Para cada série de dados, primeiro identificamos a classe modal (a classe com a maior frequência) e então aplicamos a fórmula para calcular a moda.
Dados agrupadados - Exemplo
| X | (34,36] | (36,38] | (38,40] | (40,42] | (42,44] | (44,46] | (46,48] | (48,50] |
| PM | 35 | 37 | 39 | 41 | 43 | 45 | 47 | 49 |
| fa | 3 | 10 | 9 | 5 | 12 | 2 | 8 | 1 |
| fr | 0.06 | 0.20 | 0.18 | 0.10 | 0.24 | 0.04 | 0.16 | 0.02 |
| Fa | 3 | 13 | 22 | 27 | 39 | 41 | 49 | 50 |
| Fr | 0.06 | 0.26 | 0.44 | 0.54 | 0.78 | 0.82 | 0.98 | 1.00 |
Dados agrupadados - Exemplo
\(Mo(X) = l+\left( \dfrac{d_1}{d_1+d_2}\right) \times h,\)
onde:
Classe modal: classe com maior frequência
\(l\) : é o limite inferior da classe modal;
\(d_1\): diferença entre a frequência absoluta da classe modal e a imediatamente anterior;
\(d_2\): diferença entre a frequência absoluta da classe modal e a imediatamente posterior;
\(h\): amplitude da classe modal.
Dados agrupadados - Exemplo
- O método mais simples para o cálculo da moda consiste em tomar o ponto médio da classe modal.
Mediana
Dados não agrupados
- Considere o tempo (segundos) de cinco tarefas realizadas por uma CPU:\(30, 25, 28, 33, 31\)
- Considere o tempo (segundos) de seis tarefas realizadas por uma CPU:\(30, 25, 28, 33, 31,32\)
Dados não agrupados
- Consideremos, agora, as observações ordenadas em ordem crescente. Vamos denotar a menor observação por \(x_{(1)}\), a segunda por \(x_{(2)}\), e assim por diante, obtendo-se
\[x_{(1)} \leq x_{(2)} \leq \ldots \leq x_{(n-1)} \leq x_{(n)}\]
Dados não agrupados
- Com esta notação, a mediana da variável \(X\) pode ser definida por
Dados não agrupados
- A tabala abaixo mostra o tempo gasto (segundos) de uma CPU na realização de 20 tarefas. Obtenha a mediana.
Dados não agrupados
| X | fa | fr | Fa | Fr |
|---|---|---|---|---|
| 35 | 1 | 0.05 | 1 | 0.05 |
| 36 | 6 | 0.30 | 7 | 0.35 |
| 37 | 9 | 0.45 | 16 | 0.80 |
| 38 | 2 | 0.10 | 18 | 0.90 |
| 39 | 1 | 0.05 | 19 | 0.95 |
| 40 | 1 | 0.05 | 20 | 1.00 |
Dados agrupadados - Exemplo
- A tabala abaixo mostra o tempo gasto (segundos) de uma CPU na realização de 50 tarefas
- Para cada série de dados, primeiro identificamos a classe mediana (a classe que acumula 50% das observações) e então aplicamos a fórmula para calcular a mediana.
Dados agrupadados - Exemplo
| X | (34,36] | (36,38] | (38,40] | (40,42] | (42,44] | (44,46] | (46,48] | (48,50] |
| PM | 35 | 37 | 39 | 41 | 43 | 45 | 47 | 49 |
| fa | 3 | 10 | 9 | 5 | 12 | 2 | 8 | 1 |
| fr | 0.06 | 0.20 | 0.18 | 0.10 | 0.24 | 0.04 | 0.16 | 0.02 |
| Fa | 3 | 13 | 22 | 27 | 39 | 41 | 49 | 50 |
| Fr | 0.06 | 0.26 | 0.44 | 0.54 | 0.78 | 0.82 | 0.98 | 1.00 |
Dados agrupadados - Exemplo
- A fórmula usada é dada por:
\[Md(X) = l + \left( \dfrac{n/2 - F}{f_{a_{cm}}} \right) \times h,\]
Dados agrupadados - Exemplo
onde:
- Classe mediana: classe que acumula 50% das observações.
- \(l\) : é o limite inferior da classe mediana;
- \(n\): número total de elementos;
- \(F\): frequência absoluta acumulada até a classe anterior à classe mediana;
- \(f_{a_{cm}}\): frequência absoluta da classe mediana;
- \(h\): amplitude da classe mediana.
Observações
- Média.
- Vantagens: é a mais usada das medidas, existe em qualquer variável quantitativa, leva em conta todos os valores da amostra e é usada em muitos métodos estatísticos.
- Desvantagem: é afetada por valores extremos.
Observações
- Mediana.
- Vantagens: é usada com frequência, existe em qualquer variável quantitativa e não é afetada por valores extremos.
- Desvantagem: não leva em conta todos os valores no cálculo.
Observações
- Moda.
- Vantagem: Não é afetada por valores extremos.
- Desvantagens: é raramente usada, pode não existir em uma variável quantitativa, não leva em conta todos os valores e pode existir mais de uma moda em uma variável.
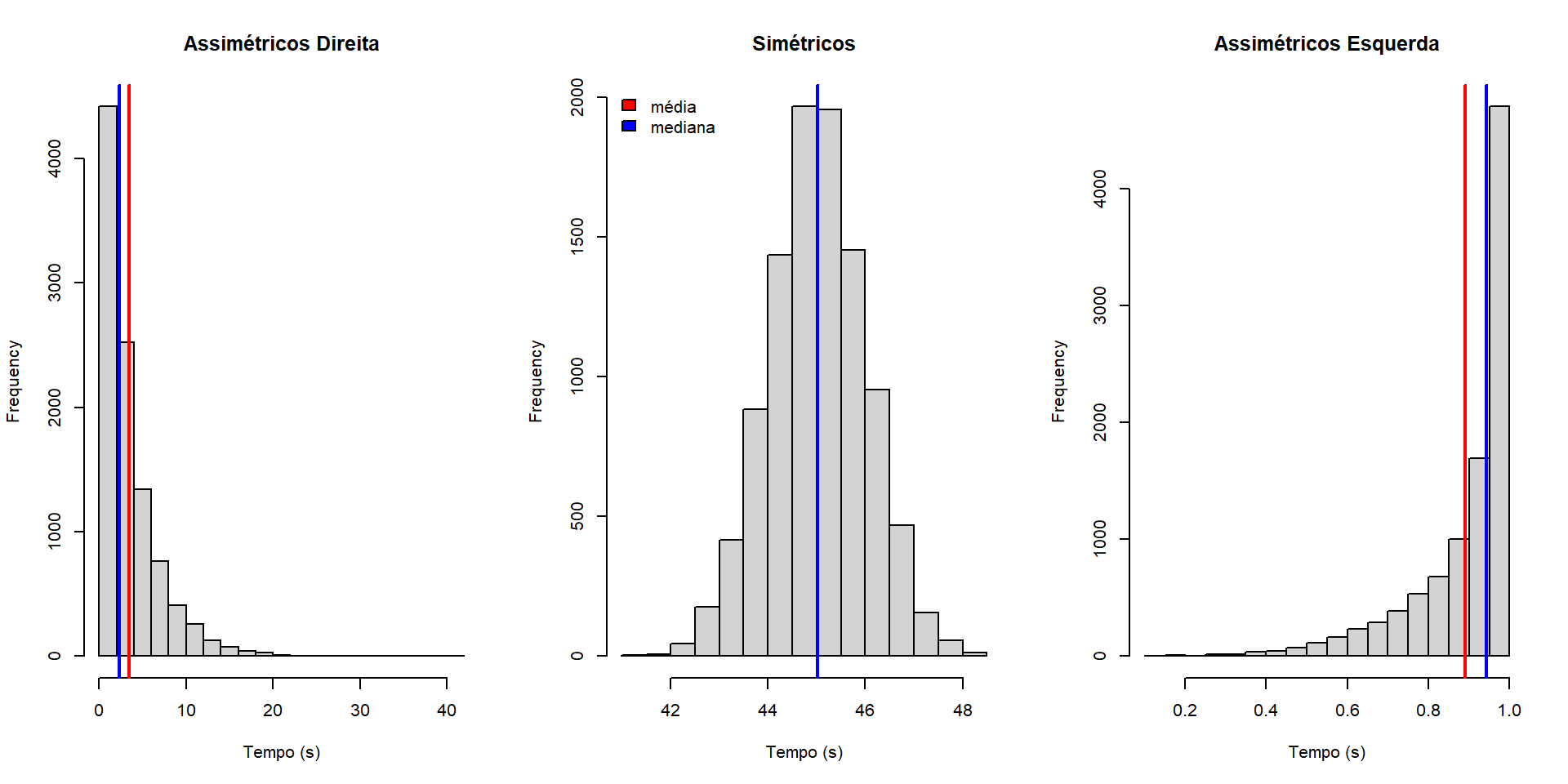
Assimetria e Simetria
Uma distribuição é simétrica quando a metade direita do gráfico é uma imagem espelhada da metade esquerda, indicando que os valores estão igualmente distribuídos em torno da média.
Nesse caso, a média, a mediana e a moda geralmente são iguais.
Assimetria e Simetria
Por outro lado, uma distribuição assimétrica ocorre quando a distribuição dos dados não é simétrica, o que significa que há uma assimetria ou distorção na forma da distribuição.
Isso pode ocorrer quando há valores extremos ou quando os dados estão inclinados para a esquerda (assimetria negativa) ou para a direita (assimetria positiva).
Assimetria e Simetria
- Nesse caso, a média, a mediana e a moda podem ser diferentes.
Assimetria e Simetria
Separatrizes
Exemplos
Determinar os 10% mais ricos ou os 25% mais pobres
Identificar os 20% de clientes que geram mais receita
10% das requisições estão enfrentando atrasos significativos
75% dos usuários do aplicativo gastam até 3 minutos nas sessões
Quartis
- Os quartis são três valores que dividem os dados em quatro partes iguais:
Primeiro quartil \(Q_1\): é o valor abaixo do qual 25% dos dados estão situados.
Segundo quartil \(Q_2\): é a mediana, divide os dados ao meio, com 50% dos dados abaixo dele.
Terceiro quartil \(Q_3\): é o valor abaixo do qual 75% dos dados estão situados.
Quartis
Para calcular os quartis, siga estes passos:
Ordene os dados em ordem crescente.
Encontre a mediana (\(Q_2\)), divide os dados em duas metades.
\(Q_1\) é o número que está na metade inferior dos dados (do menor valor até \(Q_2\)).
\(Q_3\) é o número que está da metade superior dos dados (de \(Q_2\) até o maior valor).
Quartis - Exemplos
- Considere os tempos, em segundos, de cinco tarefas realizadas por uma CPU: \[30; 25;20;28;33;31;32. \]
Quartis - Exemplos
Dados ordenados: 20, 25, 28, 30, 31, 32, 33
\(Q_1 = \frac{25+28}{2} = 26.5\). Portanto, 25% das tarefas foram realizadas em até 26.5 segundos
\(Q_2 = 30\). Portanto, 50% das tarefas foram realizadas em até 30 segundos
\(Q_3 = \frac{31+32}{2} = 31.5\). Portanto, 75% das tarefas foram realizadas em até 31.5 segundos
Percentis
- De forma geral, pode-se determinar o \(p\)-ésimo percentil.
- Percentil
-
O p-ésimo percentil é o valor que pelo menos \(p\) por cento das observações são menores ou iguais a esse valor e pelo menos (100 − p) por cento das observações são maiores ou iguais a esse valor.
Percentis
O procedimento a seguir pode ser usado para calcular o \(p\)-ésimo percentil.
Etapa 1: Organize os dados em ordem crescente.
Etapa 2: Calcule um índice \(i\) \[ i = \left(\frac{p}{100}\right)n \] onde \(p\) é o percentil procurado e \(n\) é o número de observações.
Percentis
Etapa 3:
- Se \(i\) não for um número inteiro, arredonde-o para cima. O próximo número inteiro maior do que \(i\) denota a posição do \(p\)-ésimo percentil.
- Se \(i\) for um número inteiro, o \(p\)-ésimo percentil será a média dos valores que ocupam as posições \(i\) e \(i+1\).
Percentis - Exemplos
10% 20% 25% 50% 75% 90%
23.0 25.6 26.5 30.0 31.5 32.4 20% das tarefas foram realizadas em até 25.6 segundos
90% das tarefas foram realizadas em até 32.4 segundos
Observação: às vezes são utilizadas outras convenções para calcular os percentis, e os valores reais atribuídos aos percentis podem variar ligeiramente. Para mais informações, digite:
?quantile