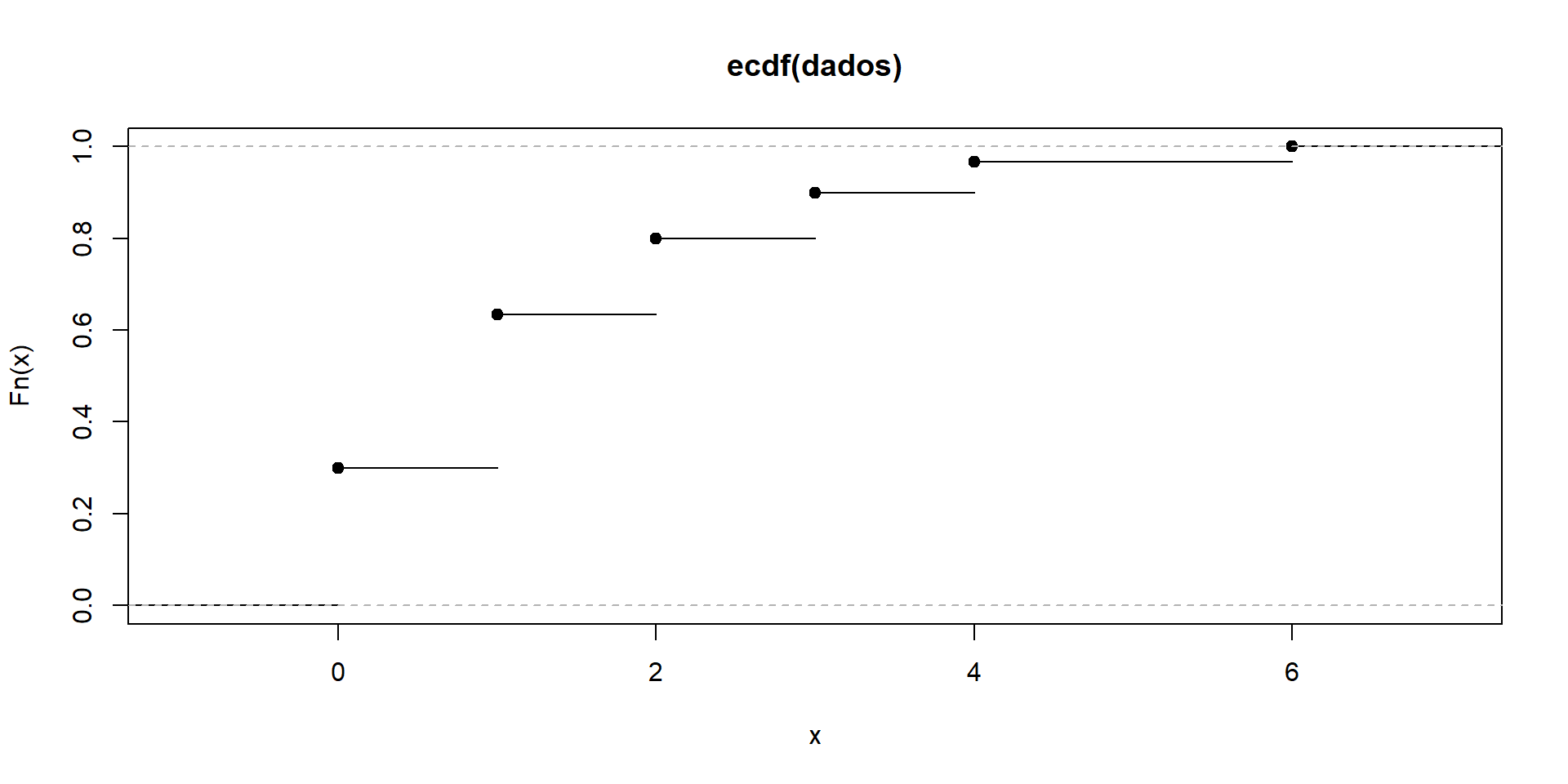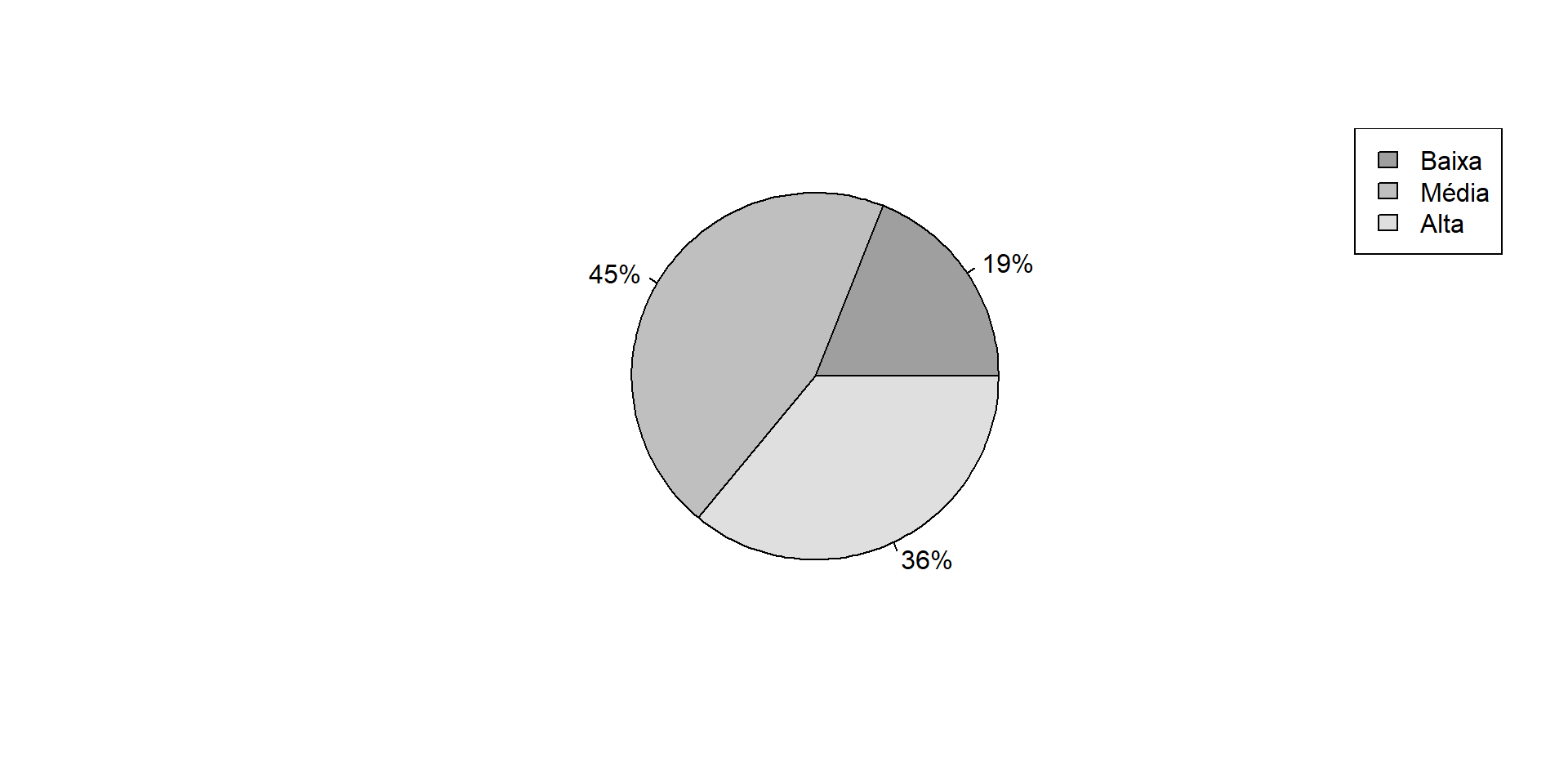
dados <- c(1, 3, 1, 1, 0, 1, 0, 1, 1, 0, 2, 2, 0, 0, 0, 1, 2, 1, 2, 0, 0, 1, 6, 4, 3, 3, 1, 2, 4, 0)
length(dados) # tamnho dos dados[1] 30Quando se estuda uma variável, o maior interesse do pesquisador é conhecer o comportamento dessa variável, analisando a ocorrência de suas possíveis realizações.
As tabelas de distribuição de frequência permitem identificar características dos dados em análise. Elas podem ser: simples, intervalares e dupla entrada
Dados brutos: valores coletados, sem tratamento ,os seguintes valores poderiam ser os dados brutos: 24, 23, 22, 28, 35, 21, 23, 33.
Rol: é o arranjo dos dados brutos em ordem de frequência crescente ou decrescente. Os dados brutos anteriores ficariam assim: 21, 22, 23, 23, 24, 28, 33, 35.
Amplitude Total (AT): é a diferença entre o maior e o menor valor observado, \(AT = \text{maior valor} - \text{menor valor}\). No exemplo, \(AT = 35 - 21 = 14\).
Classe: é cada um dos grupos de valores em que se subdivide a amplitude total do conjunto de valores observados da variável.
Limite de Classe: são os valores extremos do intervalo de classe. Exemplo: No intervalo de classe \(75|--85\) ou \([75,85)\) ou \([75,85[\), o limite inferior (LI) é representado pelo valor 75, inclusive, e o valor 85 representa o limite superior (LS), exclusive, do intervalo de classe.
Ponto Médio do Intervalo de Classe (\(x_i\) ou \(PM_i\)): é o valor que representa a classe para o cálculo de certas medidas. Ele é obtido através da seguinte razão: \(PM_i = \frac{LS+LI}{2}\). O ponto médio da classe \([75,85)\) é \[PM = \frac{LS+LI}{2} = \frac{85+75}{2}=80.\]
Observação: Amplitude da Classe é dada por: \(AC = LS-LI\)
Frequência absoluta ou observada (\(f_a\)): é o número de vezes que o elemento aparece na amostra, ou o número de elementos pertencentes a uma classe.
Frequência relativa (\(f_r\)): é o valor da frequência absoluta dividido pelo número total de observações: \(f_r = \frac{f_a}{n}\). A soma de todas as frequências é igual a 1. A \(f_r\) é apresentada como proporção (valor entre 0 e 1) ou como percentual (valor entre 0 e 100) \(f_r = \frac{f_a}{n} \times 100\).
Frequência absoluta acumulada (\(F_{a}\)): corresponde ao total acumulado das \(f_a\) observadas até no nível em questão (inclusive).
Frequência relativa acumulada (\(F_{r}\)): corresponde ao total acumulado das \(f_r\) observadas até no nível em questão (inclusive).
Determine:
A ideia básica é dividir os valores em determinadas classes ou intervalos;
Embora não exista uma regra única para a determinação do tamanho e da quantidade de classes, devem-se observar as seguintes indicações:
O extremo superior de uma classe é o extremo inferior da classe subsequente;
Cada valor observado deve enquadrar-se em apenas uma classe;
A quantidade de classes, de modo geral, não deve ser inferior a 5 ou superior a 25.
\[ 17, 19, 21, 26, 29, 31, 32, 33, \\ 37, 38, 40, 41, 42, 43, 44, 47, \\ 47, 48, 53, 54, 58, 59, 60, 63. \]
Apresente a distribuição de frequências (Intervalos) da variável tempo.
Qual a proporção de estudantes que gastam pelo menos 41 minutos?
Qual a proporção de estudantes que gastam entre 25 e 49 minutos (inclusive)?
Qual a proporção de estudantes que gastam menos do que 41 minutos?
dados <- c(17, 19, 21, 26, 29, 31, 32, 33,
37, 38, 40, 41, 42, 43, 44, 47,
47, 48, 53, 54, 58, 59, 60, 63)
# obtendo o número de classes
HIST = hist(dados,plot = F)
inter.class = cut(dados,breaks = HIST$breaks)
head(inter.class)[1] (10,20] (10,20] (20,30] (20,30] (20,30] (30,40]
Levels: (10,20] (20,30] (30,40] (40,50] (50,60] (60,70]dados <- c(17, 19, 21, 26, 29, 31, 32, 33,
37, 38, 40, 41, 42, 43, 44, 47,
47, 48, 53, 54, 58, 59, 60, 63)
# obtendo o número de classes
HIST = hist(dados,plot = F)
inter.class = cut(dados,breaks = HIST$breaks,right=F)
head(inter.class)[1] [10,20) [10,20) [20,30) [20,30) [20,30) [30,40)
Levels: [10,20) [20,30) [30,40) [40,50) [50,60) [60,70)empregados = read.table("../../dados/empregados.txt",sep=";",header = T)
tab.abs = table(Y=empregados$reg_procedencia,
X = empregados$grau_instrucao) |> addmargins()
knitr::kable(tab.abs,booktabs = TRUE)| ensino fundamental | ensino médio | superior | Sum | |
|---|---|---|---|---|
| capital | 4 | 5 | 2 | 11 |
| interior | 3 | 7 | 2 | 12 |
| outra | 5 | 6 | 2 | 13 |
| Sum | 12 | 18 | 6 | 36 |
4 indivíduos procedem da capital e possuem o ensino fundamental;
11 indivíduos são da capital;
18 individuos possuem o ensino médio
Note que na última coluna está representada a frequência absoluta da variável \(Y\)
Note que na última linha está representada a frequência absoluta da variável \(X\)
As frequências da parte interna da tabela são chamadas de frequências absolutas conjunta entre \(X\) e \(Y\).
Ao invés de trabalharmos com frequência absoluta, podemos construir tabelas com a frequência relativa (proporções). Nesse caso, podemos considerar três possibilidades para expressar a proporção:
em relação ao total;
em relação ao total de cada coluna;
em relação ao total de cada linha.
11% dos empregados vêm da capital e têm o ensino fundamental
Os totais nas margens fornecem as distribuições unidimensional de cada uma da variável, 31% dos indivíduos vêm da capital.
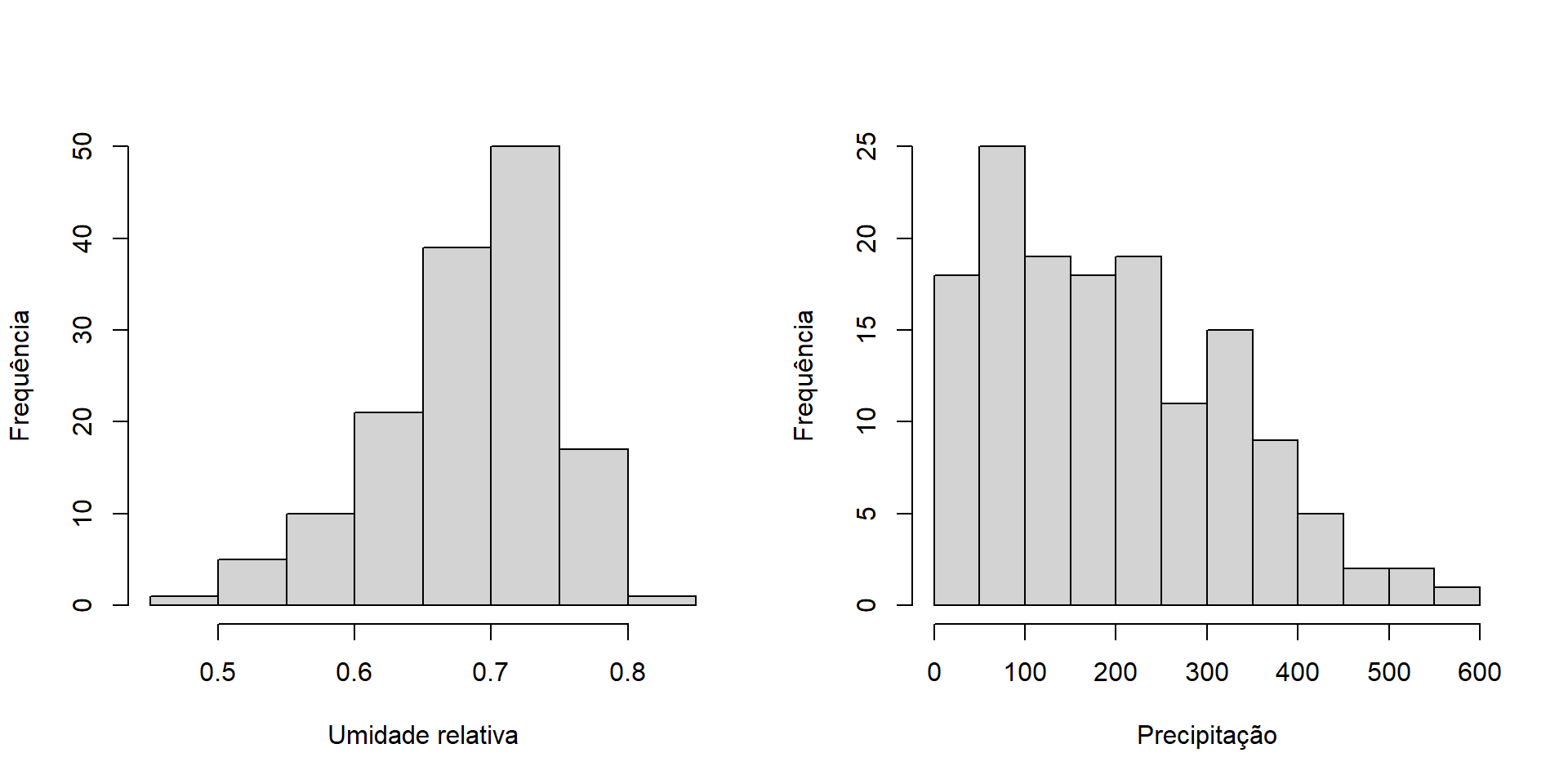
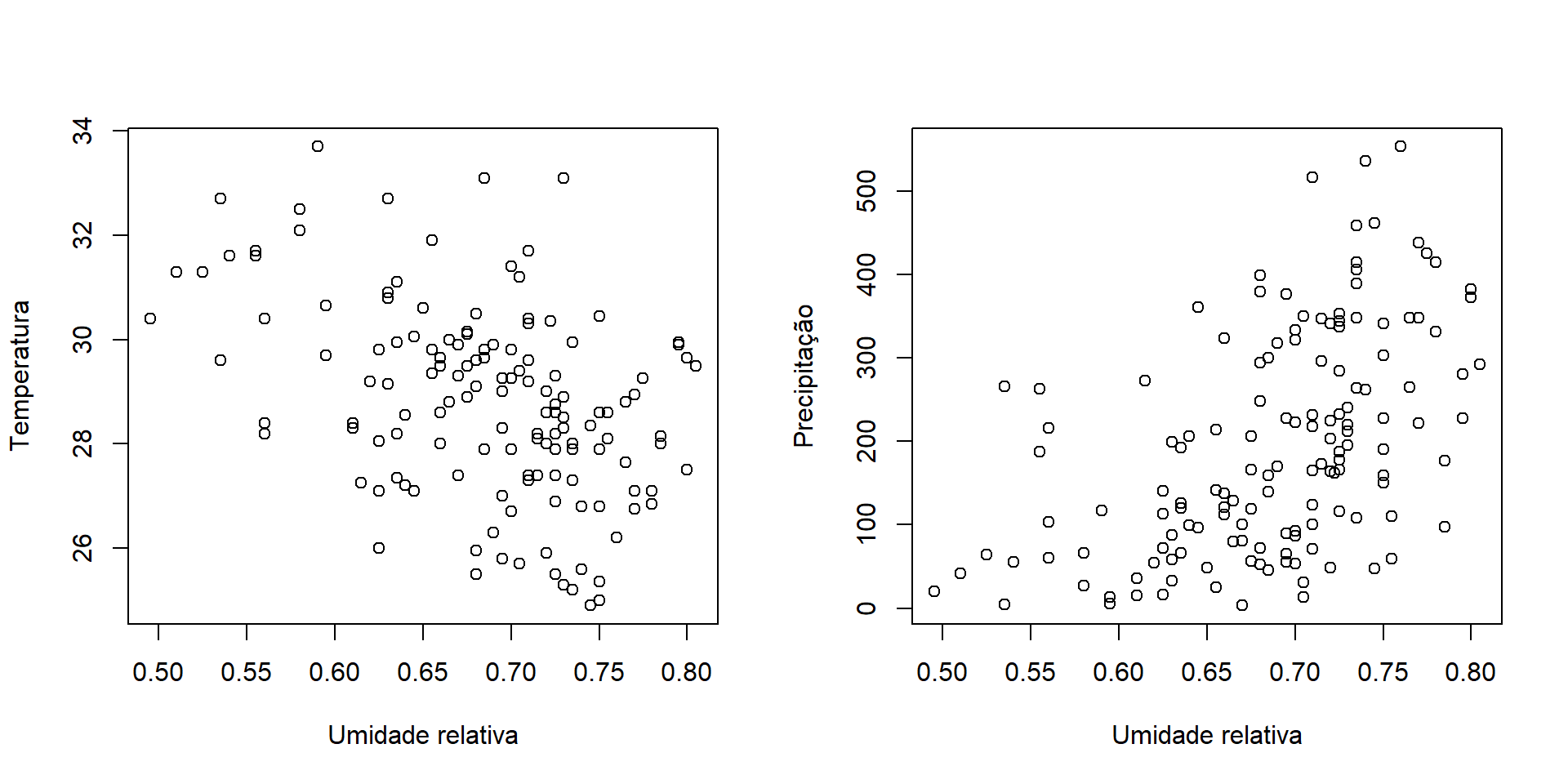
Os gráficos desempenham um papel crucial na análise de dados, fornecendo uma representação visual que facilita a compreensão e interpretação das informações.
Será apresentado os seguintes gráficos: histogramas, densidades, barras, setores, dispersão, linha, boxplot, distribuição acumulada
# A tibble: 6 × 8
cidade year month month_names rh tbs tbu precp
<chr> <chr> <chr> <fct> <dbl> <dbl> <dbl> <dbl>
1 Barcelos 2000 01 Jan 0.83 28.1 26 275.
2 Barcelos 2000 02 Feb 0.785 27 26.2 121.
3 Barcelos 2000 03 Mar 0.745 25.1 24.7 236.
4 Barcelos 2000 04 Apr 0.8 28.3 25.9 406.
5 Barcelos 2000 05 May 0.805 25.5 25.1 370
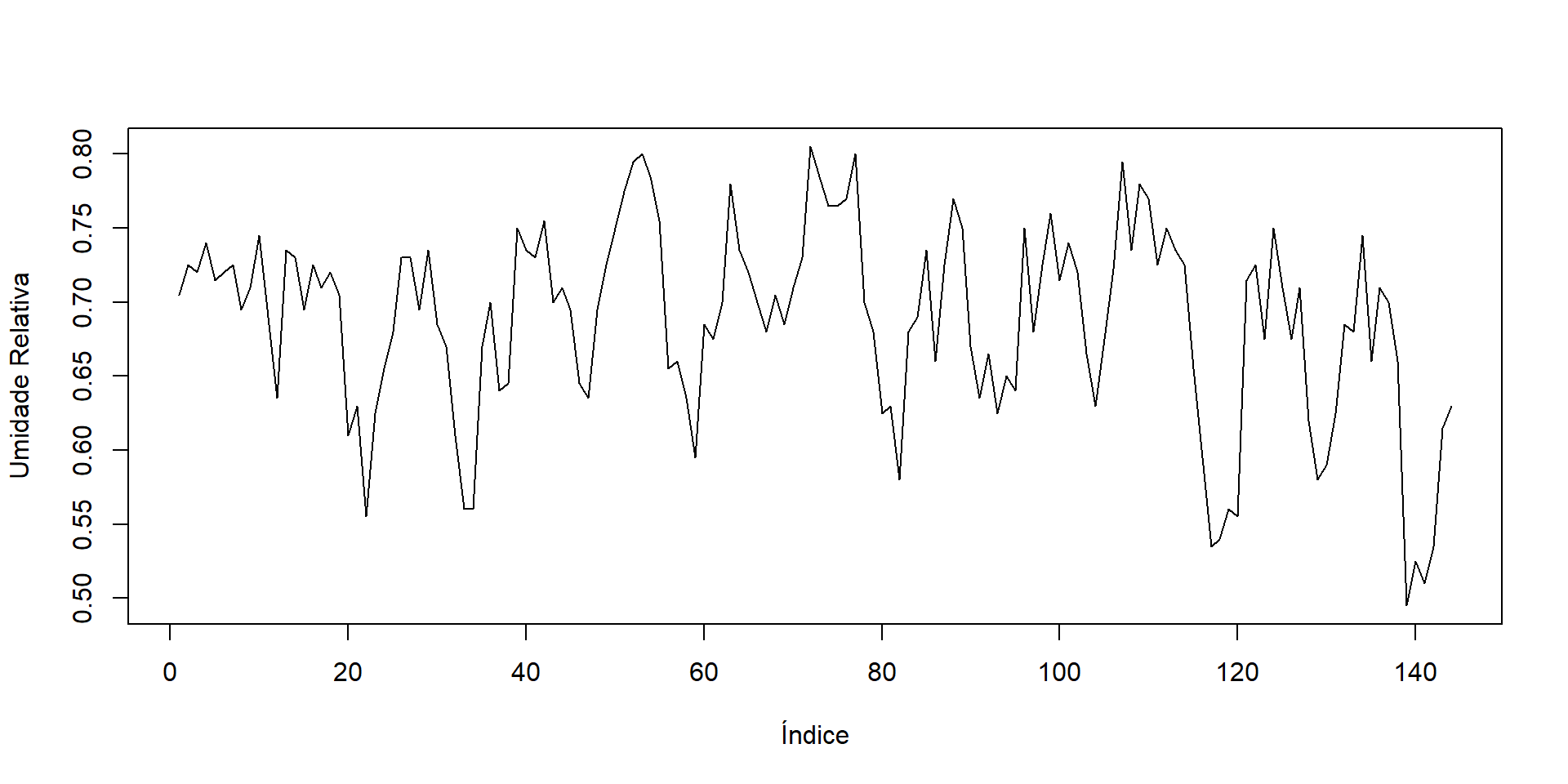
6 Barcelos 2000 06 Jun 0.76 25.7 24.6 180.rh: menor média diária da umidade relativa
tbs (temperatura bulbo seco): tbs do dia em que ocorreu a menor média diária de “rh”
tbu (temperatura bulbo úmido): tbu do dia em que ocorreu a menor média diária de “rh”
precp: precipitação (mm) no mês
tibble [2,016 × 8] (S3: tbl_df/tbl/data.frame)
$ cidade : chr [1:2016] "Barcelos" "Barcelos" "Barcelos" "Barcelos" ...
$ year : chr [1:2016] "2000" "2000" "2000" "2000" ...
$ month : chr [1:2016] "01" "02" "03" "04" ...
$ month_names: Factor w/ 12 levels "Apr","Aug","Dec",..: 5 4 8 1 9 7 6 2 12 11 ...
$ rh : num [1:2016] 0.83 0.785 0.745 0.8 0.805 0.76 0.765 0.745 0.725 0.75 ...
$ tbs : num [1:2016] 28.1 27 25.1 28.3 25.5 25.7 27.3 26.5 29.4 28.4 ...
$ tbu : num [1:2016] 26 26.2 24.7 25.9 25.1 24.6 26.4 24.3 25.9 25.4 ...
$ precp : num [1:2016] 275 121 236 406 370 ...
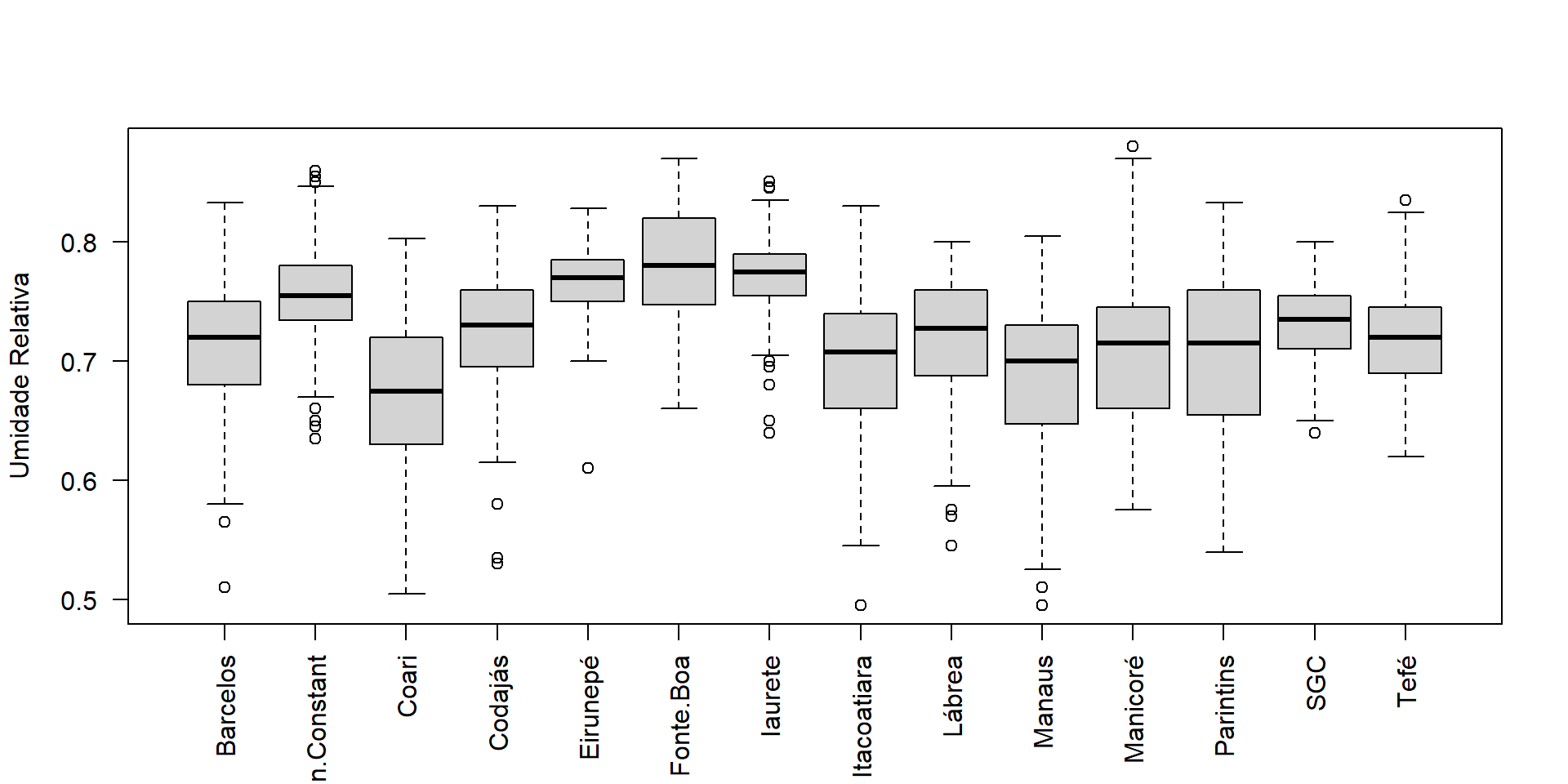
Barcelos Benjamin.Constant Coari Codajás
144 144 144 144
Eirunepé Fonte.Boa Iaurete Itacoatiara
144 144 144 144
Lábrea Manaus Manicoré Parintins
144 144 144 144
SGC Tefé Sum
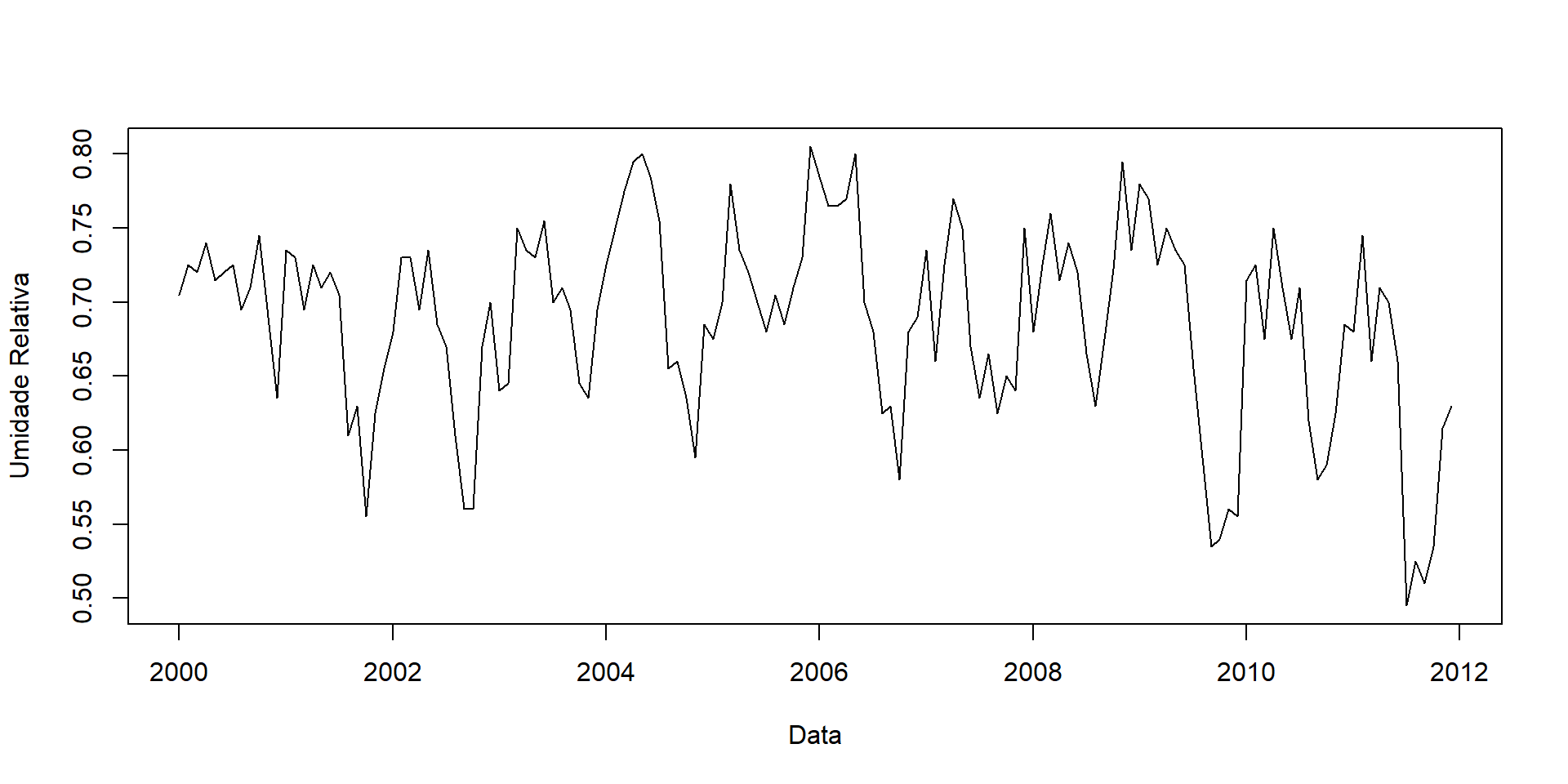
144 144 2016 Jan Feb Mar Apr May Jun Jul
2000 0.7050000 0.7250000 0.7200000 0.7400000 0.7150000 0.7200000 0.7250000
2001 0.7350000 0.7300000 0.6950000 0.7250000 0.7100000 0.7200000 0.7050000
2002 0.6800000 0.7300000 0.7300000 0.6950000 0.7350000 0.6850000 0.6700000
2003 0.6400000 0.6450000 0.7500000 0.7350000 0.7300000 0.7550000 0.7000000
2004 0.7250000 0.7500000 0.7750000 0.7950000 0.8000000 0.7850000 0.7550000
2005 0.6750000 0.7000000 0.7800000 0.7350000 0.7200000 0.7000000 0.6800000
2006 0.7850000 0.7650000 0.7650000 0.7700000 0.8000000 0.7000000 0.6800000
2007 0.7350000 0.6600000 0.7250000 0.7700000 0.7500000 0.6700000 0.6350000
2008 0.6800000 0.7250000 0.7600000 0.7150000 0.7400000 0.7200000 0.6650000
2009 0.7800000 0.7700000 0.7250000 0.7500000 0.7350000 0.7250000 0.6550000
2010 0.7150000 0.7250000 0.6750000 0.7500000 0.7100000 0.6750000 0.7100000
2011 0.6800000 0.7450000 0.6600000 0.7100000 0.7000000 0.6600000 0.4950000
Aug Sep Oct Nov Dec
2000 0.6950000 0.7100000 0.7450000 0.6900000 0.6350000
2001 0.6100000 0.6300000 0.5550000 0.6250000 0.6550000
2002 0.6100000 0.5600000 0.5600000 0.6700000 0.7000000
2003 0.7100000 0.6950000 0.6450000 0.6350000 0.6950000
2004 0.6550000 0.6600000 0.6350000 0.5950000 0.6850000
2005 0.7050000 0.6850000 0.7100000 0.7300000 0.8050000
2006 0.6250000 0.6300000 0.5800000 0.6800000 0.6900000
2007 0.6650000 0.6250000 0.6500000 0.6400000 0.7500000
2008 0.6300000 0.6750000 0.7222516 0.7950000 0.7350000
2009 0.5950000 0.5350000 0.5400000 0.5600000 0.5550000
2010 0.6200000 0.5800000 0.5900000 0.6250000 0.6850000
2011 0.5250000 0.5100000 0.5350000 0.6150000 0.6300000Dados categóricos ou discretos.
Exibir a proporção de cada categoria em relação ao todo. Facilita a comparação de partes com o todo.
require(tidyverse)
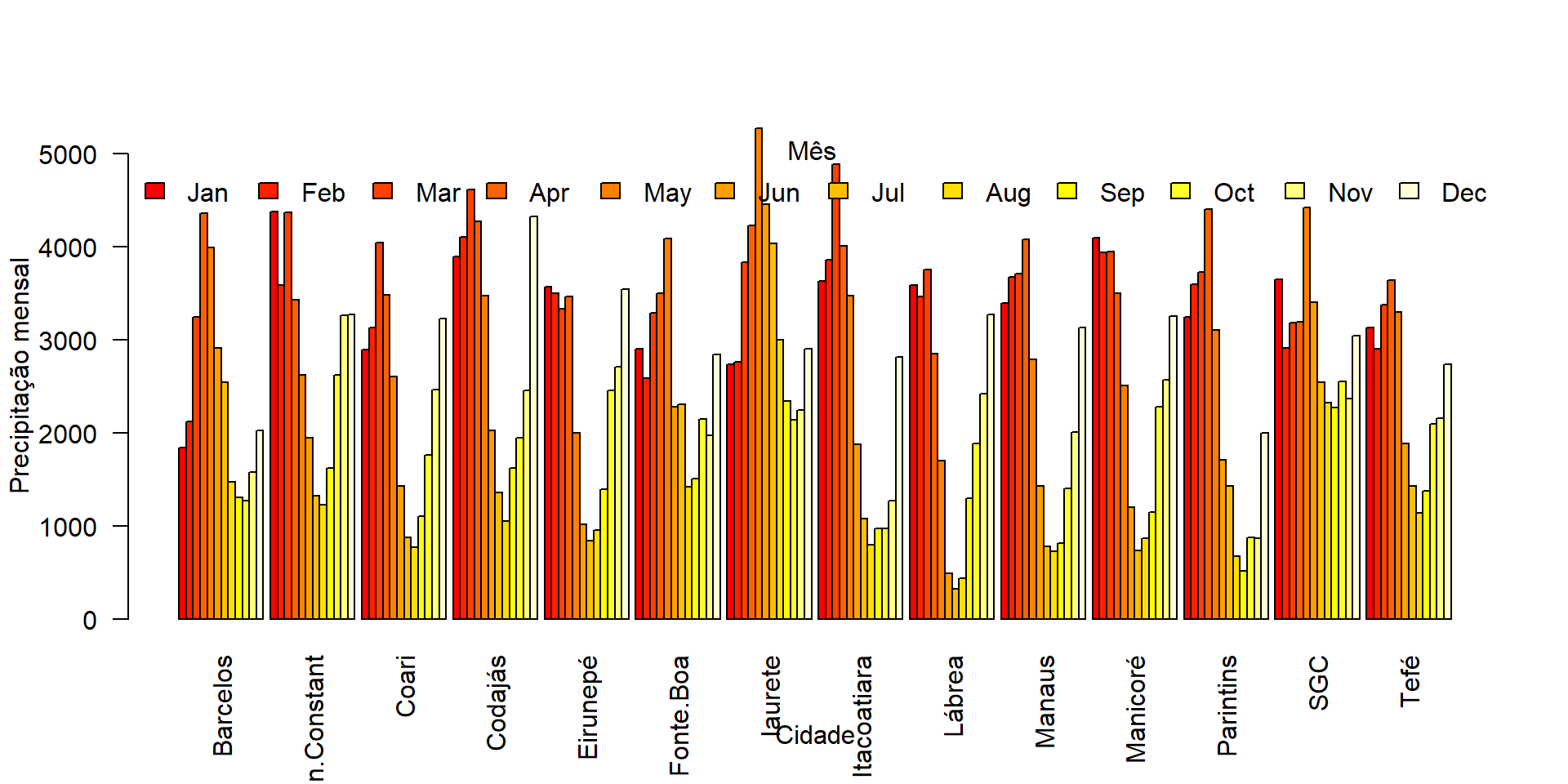
precp.mes.total = dados %>% group_by(cidade,month) %>%
summarise(total = sum(precp)|> round())
precp.mes.total# A tibble: 168 × 3
# Groups: cidade [14]
cidade month total
<chr> <chr> <dbl>
1 Barcelos 01 1842
2 Barcelos 02 2117
3 Barcelos 03 3240
4 Barcelos 04 4359
5 Barcelos 05 3985
6 Barcelos 06 2910
7 Barcelos 07 2545
8 Barcelos 08 1468
9 Barcelos 09 1304
10 Barcelos 10 1265
# ℹ 158 more rowsBase simulada usando o programa R
Emails de 100 remetentes
remetente assunto tamanho_kb prioridade spam
1 Ana-Ribeiro@example.com Confirmação de Pedido 195 Média TRUE
2 Rafael-Martins@example.com Atualização de Conta 467 Média TRUE
3 Fernanda-Pereira@example.com Convite para Evento 342 Alta TRUE
4 Ana-Almeida@example.com Atualização de Conta 224 Média TRUE
5 Mariana-Silva@example.com Confirmação de Pedido 68 Média TRUE
6 Maria-Silva@example.com Oferta Especial 474 Baixa TRUE
qtd_caracteres formato
1 241 Texto
2 115 Texto
3 55 Texto
4 246 HTML
5 159 HTML
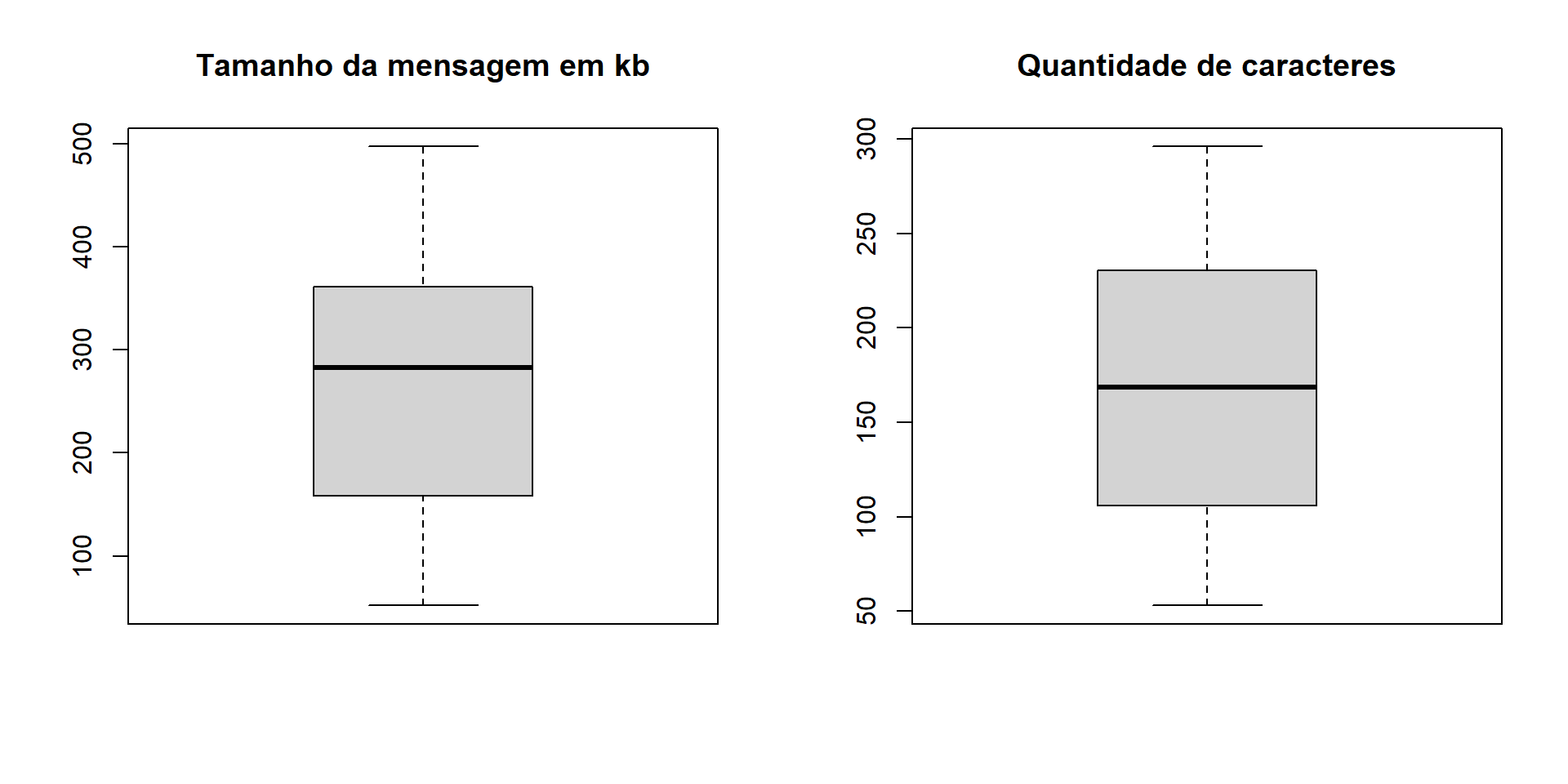
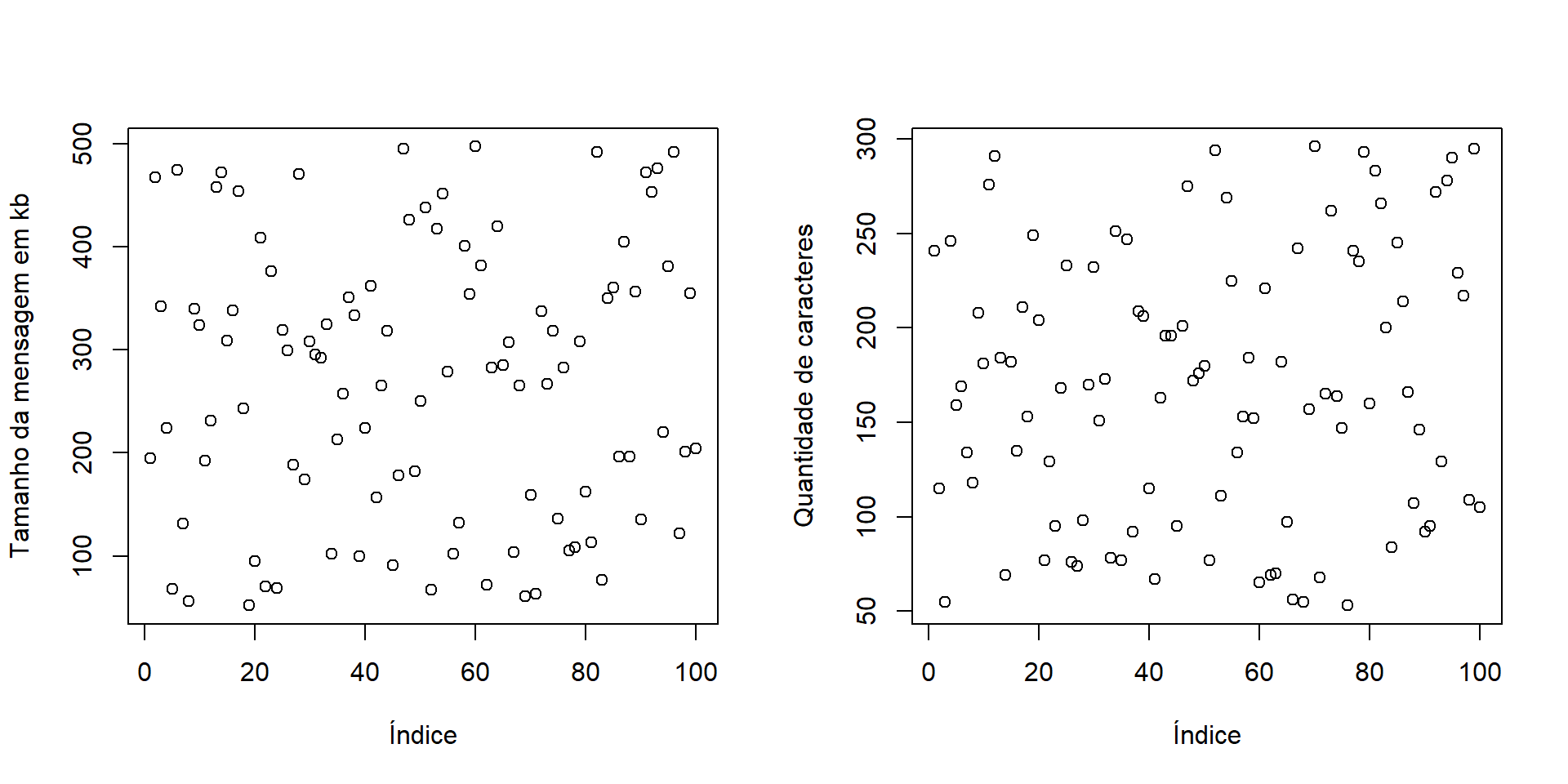
6 169 Texto'data.frame': 100 obs. of 7 variables:
$ remetente : chr "Ana-Ribeiro@example.com" "Rafael-Martins@example.com" "Fernanda-Pereira@example.com" "Ana-Almeida@example.com" ...
$ assunto : chr "Confirmação de Pedido" "Atualização de Conta" "Convite para Evento" "Atualização de Conta" ...
$ tamanho_kb : num 195 467 342 224 68 474 131 56 340 324 ...
$ prioridade : chr "Média" "Média" "Alta" "Média" ...
$ spam : logi TRUE TRUE TRUE TRUE TRUE TRUE ...
$ qtd_caracteres: num 241 115 55 246 159 169 134 118 208 181 ...
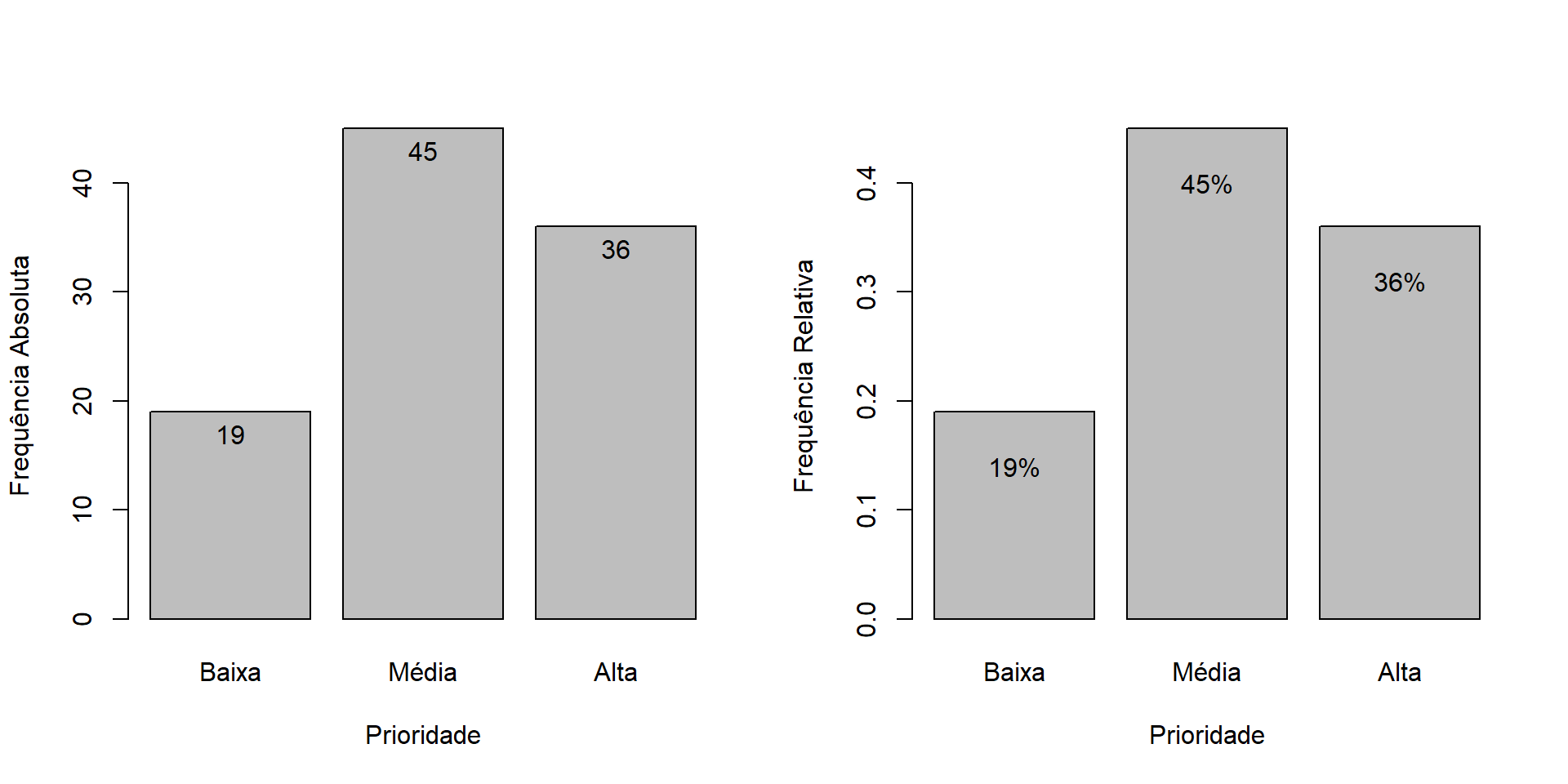
$ formato : chr "Texto" "Texto" "Texto" "HTML" ...par(mfrow=c(1,2))
LABELS.1 = paste(tabela,sep = "")
bar_1 = barplot(tabela,xlab = "Prioridade",ylab="Frequência Absoluta")
text(x = bar_1,y = tabela-2,labels = LABELS.1)
bar_2 = barplot(tabela.prop,xlab = "Prioridade",ylab="Frequência Relativa")
LABELS.2 = paste(tabela.prop*100,"%",sep = "")
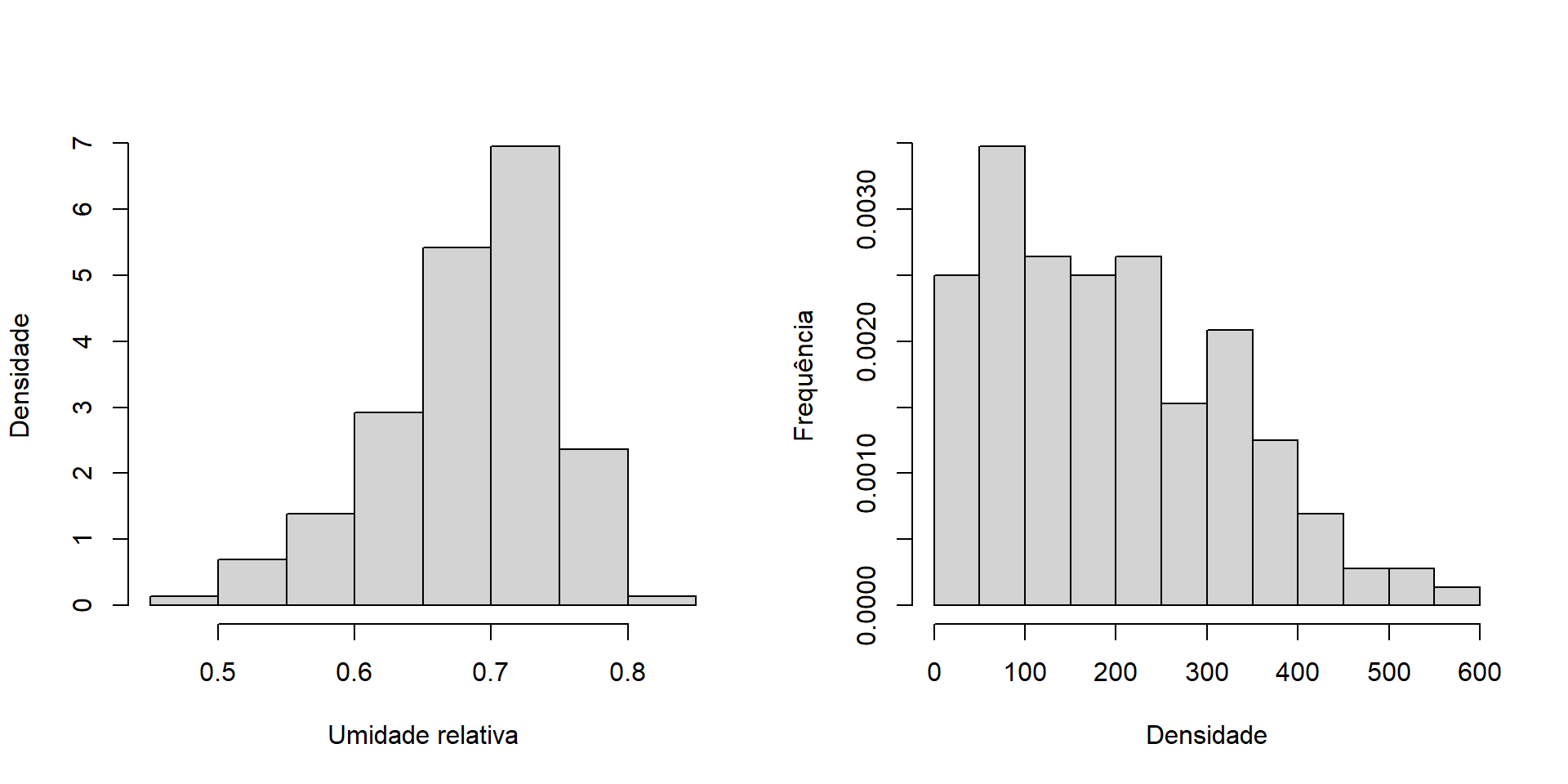
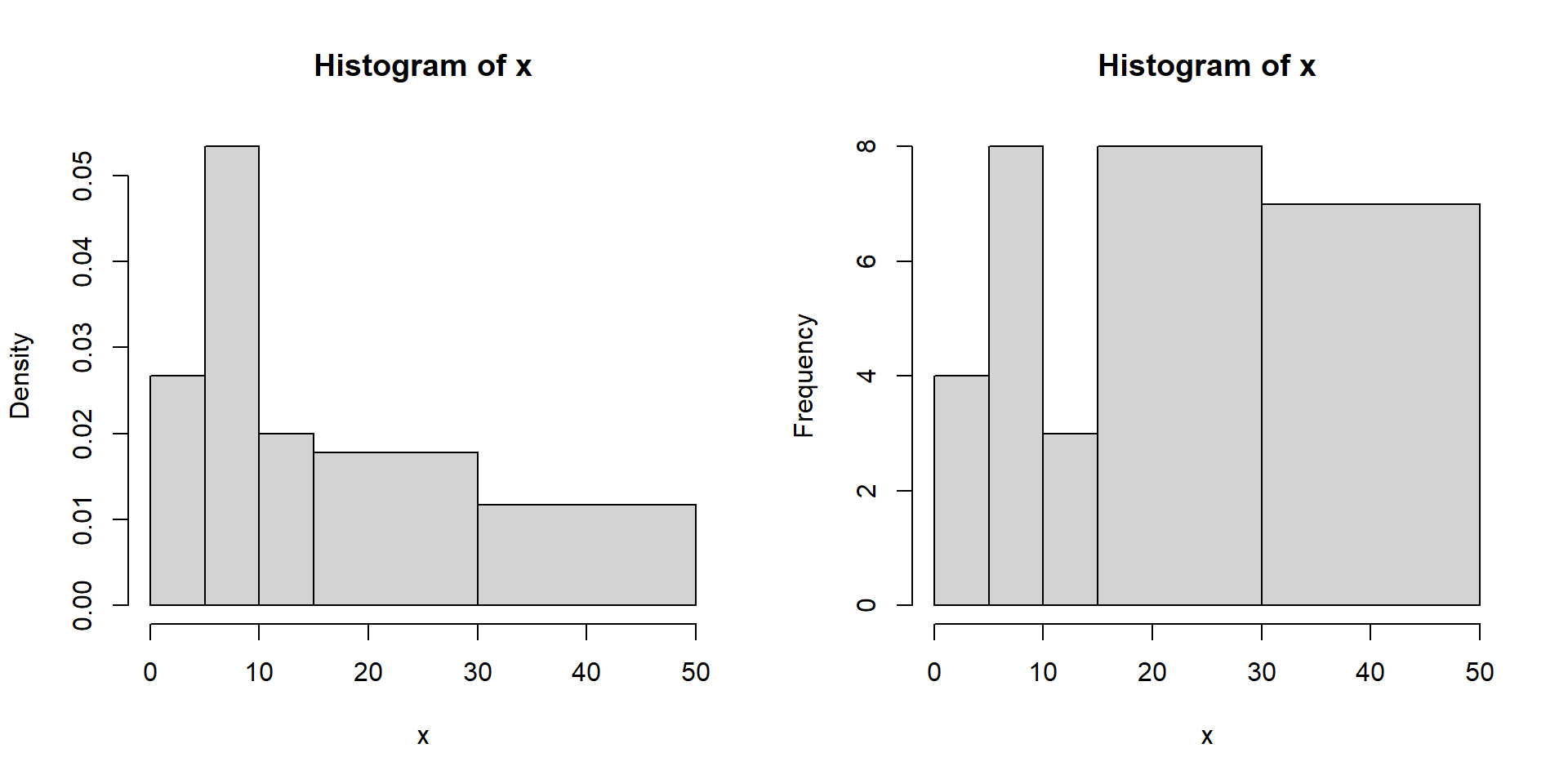
text(x = bar_1,y = tabela.prop-0.05,labels = LABELS.2)A densidade nos ajuda a entender a frequência relativa dos tempos gastos em cada intervalo, normalizando pela largura do intervalo.
Isso é útil para comparar distribuições de frequência quando os intervalos têm tamanhos diferentes.