Probabilidade e Estatística
Conceitos Iniciais
O que é Estatística?
Exemplo - Compra da TV
Suponha que você queira comprar uma televisão e quer saber qual é a loja que apresenta o melhor preço. O que você faz?
Define as características da televisão que você deseja;
Você inicia sua pesquisa nas lojas anotando os preços dos televisores;
Depois você compara os preços de cada loja;
Após comparar os preços, você seleciona aquela loja com melhor preço e se dirige até ela para efetuar a sua compra.
Exemplo - Compra da TV (Continuação)
Note que a Estatística estava presente quando você:
Definiu as características da televisão;
Coletou os dados;
Extraiu as informações a partir da sua pesquisa;
Tomou decisão baseada nas informações extraídas.
Etimologia
Históricamente, a palavra “estatística” tem origem no latim “statisticus”, que significa “relativo ao Estado”;
Seu uso estava associado à coleta e análise de dados demográficos e econômicos para governos, especialmente para fins de planejamento e tomada de decisões políticas;
Ao longo do tempo, o termo foi adotado em um contexto mais amplo, abrangendo a análise de dados em diversos campos, como ciências naturais, ciências sociais, negócios e muito mais.
Definição
- Estatística
-
É a ciência que fornece os princípios e os métodos para coleta, organização, resumo, análise e interpretação de dados.
Aplicações
Aplicações Gerais
Economia: Modelagem econométrica para estudar relações entre variáveis econômicas, como oferta e demanda, inflação e desemprego;
Ciências Ambientais: Estudos para prever mudanças climáticas e seus efeitos;
Medicina: Testes clínicos para avaliar a eficácia de novos tratamentos;
Biologia: Estudos de epidemiologia para analisar a propagação de doenças em populações.
Aplicações na Área de Computação
Análisar o Tempo e a ordem de falhas de componentes eletrônicos;
A quantidade de memória alocada para a execução de determinado programa;
Quantidade de defeitos em softwares recém lançados;
Quantidade de arquivos e diretórios afetados por um vírus;
Classificar se uma mensagem é um Spam.
Artigos
Em Sullivan and Chillarege (1991) é realizado uma comparação dos defeitos regulares com os defeitos que corrompem a memória do programa;
Em Galinac Grbac and Huljenić (2015) foi analisada a distribuição de probabilidade das falhas detectadas durante a verificação em quatro versões consecutivas de um sistema de software complexo de grande escala para as centrais de telecomunicações;
Em Khalid et al. (2023) foi utilizado modelos de Machine Learning para realizar predições de defeitos em software.
Conceitos Básicos
População e Amostra
- População e Amostra
-
População é o conjunto de elementos (pessoas, objetos) que possuem pelos menos uma característica em comum de interesse do pesquisador. Amostra é qualquer subconjunto da população.
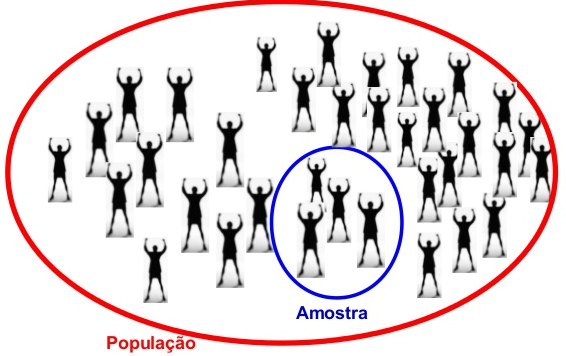
Variável
- Variável
-
É alguma característica que pode ser observada a partir da amostra.
Dados
- Dados
-
Conjuntos de valores numéricos ou não.
Exemplos
- Identifique a população, a amostra e a variável para cada um dos exemplos abaixo:
Consideremos uma pesquisa para estudar os salários dos 500 funcionários de uma empresa. Seleciona-se 36 funcionários e anotam-se os seus salários.
Um grupo de pesquisadores está interessado em estudar a preferência de linguagens de programação entre os desenvolvedores de software. Eles decidem realizar uma pesquisa online e coletam dados de uma amostra de 500 desenvolvedores.
Exemplos (Continuação)
- Uma equipe de pesquisa está investigando o impacto de diferentes configurações de hardware na Temperatura e consumo de energia em computadores pessoais durante a execução de determinado jogo. Para isso, selecionaram 50 computadores pessoais e analisaram durante 30 minutos o impacto do jogo na Temperatura e consumo de energia
Representações das variáveis
- As representações das variáveis podem ser feitas através de uma letra:
| Variável | Representação |
|---|---|
| Estado Civil | X |
| Grau de Instrução | Y |
| Número de Filhos | Z |
Classificação das Variáveis
- As variáveis podem ser classificadas em dois tipos: quantitativas/numéricas ou qualitativas/categóricas.
Quantitativas
Estão relacionadas às observações associadas a contagem ou mensurações. Elas podem ser:
Discretas: assumem somente valores inteiros em um conjunto de valores , é resultado de uma possível contagem. Exemplos: número de irmãos, número de estudantes em sala de aula;
Contínuas: assumem somente valores em um intervalo de valores. É o resultado de um processo de medição. Exemplos: temperatura, velocidade, peso, altura.
Qualitativas
Representam uma “qualidade” dos objetos da população. Também são chamadas de variáveis categóricas. Elas podem ser:
Nominal: possíveis respostas que não possuem uma ordenação natural. Exemplos: raça, sexo.
Ordinal: possíveis respostas possuem uma ordenação natural. Exemplos: Classe social, escolaridade.
Observação
- Observação: algumas variáveis podem ser classificadas em mais de um tipo dependendo da unidade usada. Por exemplo, a renda medida em salários mínimos pode ser classificada como uma variável discreta, mas pode também ser ordinal se categorizada como baixa, média e alta.
Exemplos
- Identifique e classifique as variáveis
Uma equipe de pesquisa está investigando o impacto de diferentes configurações de hardware na Temperatura e consumo de energia em computadores pessoais durante a execução de determinado jogo. Para isso, selecionaram 50 computadores pessoais e analisaram durante 30 minutos o impacto do jogo na Temperatura e consumo de energia
Quantidade de defeitos em softwares recém lançados;
Classificar se uma mensagem é um Spam.
Subdivisões da Estatística
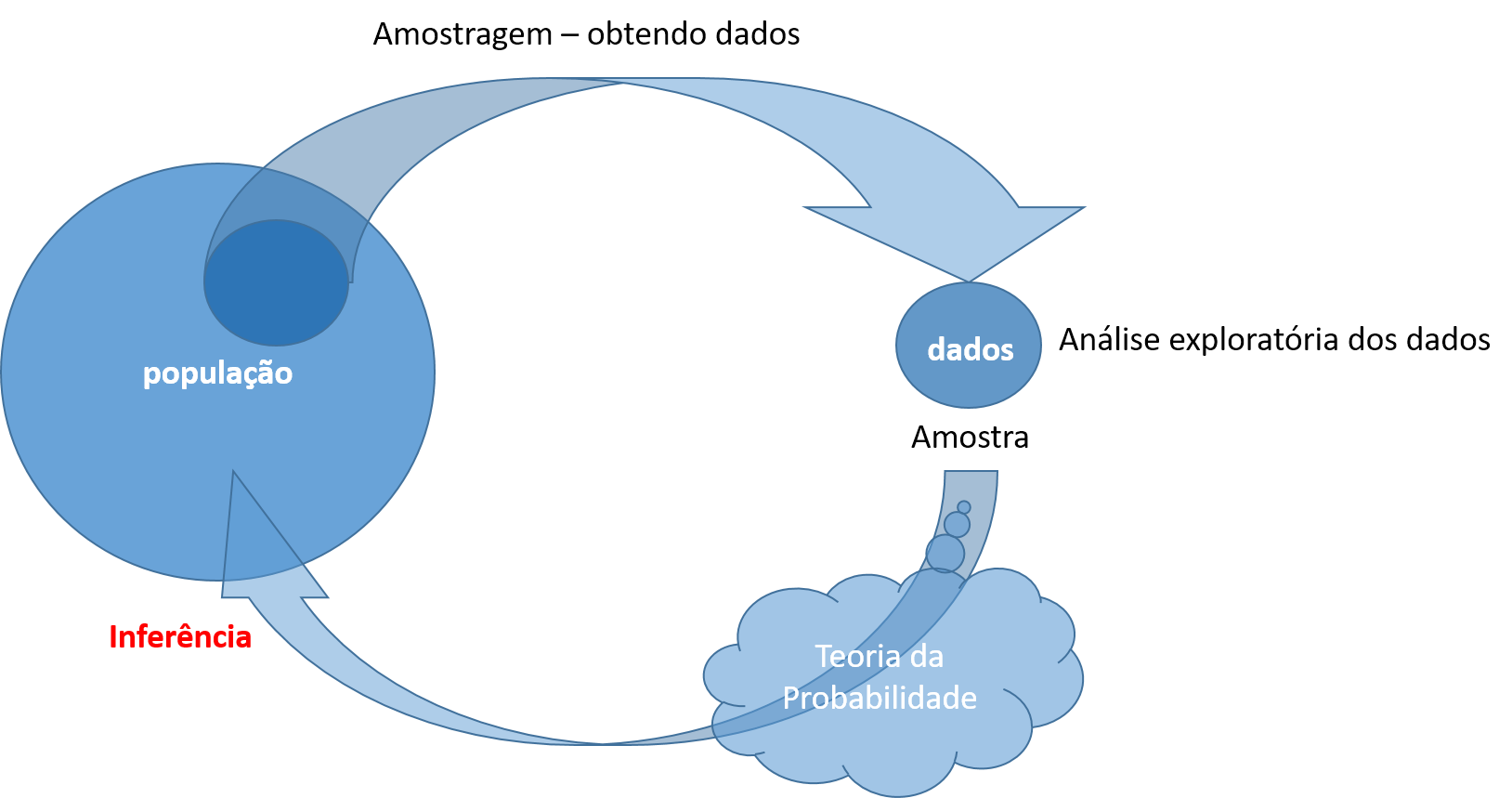
Amostragem
- Técnicas para colher amostras representativas da população;
Estatísticas Descritivas
- Em geral, é utilizada na etapa inicial da análise, em um primeiro contato com os dados. Apresenta os dados em tabelas ou gráficos além de organizar e resumir resultados preliminares.
Probabilidade
- É a teoria matemática utilizada para estudar a incerteza oriunda de fenômenos aleatório
Inferência estatística
Técnicas que tentam identificar um modelo de probabilidade para a exploração de informações e conclusões obtidas a partir de uma amostra. Pode ser dividida em teste de hipótese e estimação dos parâmetros.
Observação: Note que a inferência ocorre quando as informações são obtidas a partir de uma amostra. Não se faz inferência nos casos em que toda a população é investigada. Esse tipo de estudo, onde toda a população é considerada, é denominado censo.
Tipos de Estudos
Causa e Efeito X Associação
- Antes de definir estudos experimentais e observacionais, irei comentar sobre a diferença entre Causa e Efeito e Associção. Suponha o seguinte exemplo:
Suponha que uma equipe de pesquisadores queira investigar se a utilização de um determinado algoritmo de compressão de dados melhora o desempenho de um sistema de armazenamento em nuvem.
Eles realizam um experimento onde um grupo de servidores utiliza o algoritmo de compressão, enquanto outro grupo utiliza o armazenamento sem compressão.
Causa e Efeito X Associação
- Em seguida, eles medem métricas de desempenho, como taxa de transferência de dados e tempo de resposta do servidor, ao longo de um período de tempo.
Causa e Efeito X Associação
- Suponha o seguinte exemplo:
Suponha que uma equipe de pesquisadores esteja interessada em estudar a associação entre o uso de um determinado sistema operacional e a segurança dos dispositivos móveis.
Eles coletam dados de uma amostra de usuários de dispositivos móveis, registrando qual sistema operacional eles utilizam e quantos incidentes de segurança relataram ao longo de um período de tempo.
Causa e Efeito X Associação
- Os usuários de um sistema operacional específico relatam mais incidentes de segurança em comparação com os usuários de outros sistemas operacionais
- No entanto, eles não podem concluir que o uso desse sistema operacional causa diretamente mais incidentes de segurança, pois outros fatores podem influenciar essa relação.
Experimental X Observacional
- Suponha as seguintes situações:
- Um grupo de pesquisadores está interessado em estudar a preferência de linguagens de programação entre os desenvolvedores de software. Eles decidem realizar uma pesquisa online e coletam dados de uma amostra de 500 desenvolvedores
Experimental X Observacional
- Uma equipe de pesquisa está investigando o impacto de diferentes configurações de hardware na Temperatura e consumo de energia em computadores pessoais durante a execução de determinado jogo. Para isso, selecionaram 50 computadores pessoais e analisaram durante 30 minutos o impacto do jogo na Temperatura e consumo de energia.
Experimental X Observacional
- Experimental
-
Em um experimento, aplicamos determinado tratamento e passamos então a observar seus efeitos sobre os elementos.
Um estudo experimental envolve a manipulação de uma ou mais variáveis para observar o efeito que essa manipulação tem em outra variável.
Esse tipo de estudo é mais capaz de estabelecer causalidade, pois os pesquisadores podem controlar as condições experimentais.
Observacional
- Obervacional
-
Verificamos e medimos características específicas, mas não tentamos manipular ou modificar os elementos que estão sendo estudados.
Um estudo observacional observa e registra informações sobre um grupo, mas não tenta modificar as variáveis do ambiente
Este tipo de estudo é útil para identificar associações entre variáveis, mas não pode estabelecer causalidade definitiva.